Пост: https://t.me/ai_training_ai/33
Обучение ИИ - AI Traning
2025-10-06 12:11:08
(изм. 2025-10-06 12:23:09)
### Пост 4: Тест локальных LLM. Финальный рейтинг и все замеры
🤖 Гранд-финал: Итоги большого теста 19 локальных LLM. Кто победил?
В последнем финальном сравнении добавили результаты тестов еще 2 моделей:
Наше долгое исследование завершено! Мы протестировали 19 нейросетевых моделей и их версий, чтобы найти идеальный инструмент для автоматического извлечения данных из объявлений о недвижимости. Тесты проводились на двух совершенно разных системах:
1. GPU-стенд: Windows + Ryzen 9 9900X + NVIDIA RTX 3060.
2. CPU-сервер: Linux (окружение AlmaLinux) + AMD Ryzen 7 3700X.
После десятков тестов и анализа сотен JSON-ответов, мы готовы объявить окончательных победителей.
### методика итогового рейтинга
Для объективного сравнения мы использовали "Сводный балл" (от 0 до 10), который объединяет качество ответов (с весом 60%) и скорость работы (с весом 40%). Шкала скорости была логарифмической, чтобы справедливо оценивать модели с разной производительностью.
"Сводный балл" (от 0 до 10) — это комплексная оценка, объединяющая качество и скорость. Чем он выше, тем лучше общий баланс модели. Рассчитывается он в 3 шага:
1. Оценка качества (0-1): Балл "Качество" (от 1 до 9.9) приводится к шкале от 0 до 1, где худшая модель получает 0, а лучшая — 1.
2. Оценка скорости (0-1): Чтобы справедливо оценить скорость, мы используем логарифм времени
3. Итоговый балл: Финальный рейтинг рассчитывается как взвешенное среднее с приоритетом на качество:
---
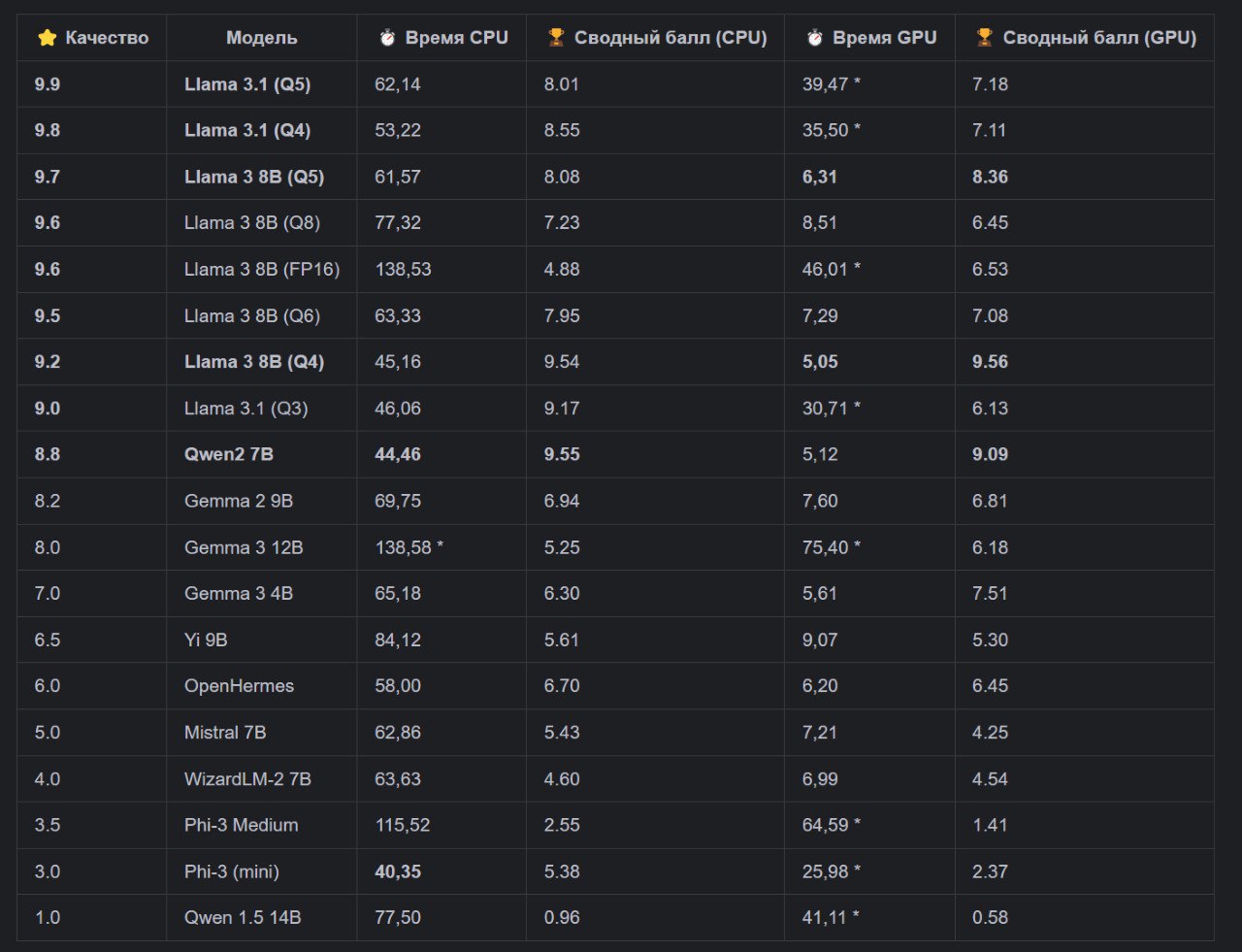
### 📜 Абсолютный и финальный рейтинг (Все модели и системы)
Главная таблица нашего исследования видна на картинке, данные в ней отсортированы по качеству.
* — запуски, где GPU использовался неэффективно (показатели скорости уровня CPU).*
---
### 🏆🏆🏆 Победители 🏆🏆🏆
#### Для системы с GPU (Windows, RTX 3060):
* Победитель: Llama 3 8B (Q4)
* Вердикт: Абсолютный чемпион по эффективности. Обеспечивает почти максимальное качество при самой высокой скорости (5,05 сек). Это идеальный выбор для быстрой работы.
#### Для системы с CPU (Linux Server):
* Победитель: 🥇 Llama 3 8B (Q4)
* Вердикт: Лучший баланс для "чистого" CPU. Хотя
Главный урок всего исследования: Не доверяйте общим бенчмаркам! Только тесты на собственном "железе" и своих задачах показывают истинную картину, выявляя программные аномалии и находя реальных, а не теоретических, чемпионов.
🤖 Гранд-финал: Итоги большого теста 19 локальных LLM. Кто победил?
В последнем финальном сравнении добавили результаты тестов еще 2 моделей:
gemma3:4b и gemma3:12b.Наше долгое исследование завершено! Мы протестировали 19 нейросетевых моделей и их версий, чтобы найти идеальный инструмент для автоматического извлечения данных из объявлений о недвижимости. Тесты проводились на двух совершенно разных системах:
1. GPU-стенд: Windows + Ryzen 9 9900X + NVIDIA RTX 3060.
2. CPU-сервер: Linux (окружение AlmaLinux) + AMD Ryzen 7 3700X.
После десятков тестов и анализа сотен JSON-ответов, мы готовы объявить окончательных победителей.
### методика итогового рейтинга
Для объективного сравнения мы использовали "Сводный балл" (от 0 до 10), который объединяет качество ответов (с весом 60%) и скорость работы (с весом 40%). Шкала скорости была логарифмической, чтобы справедливо оценивать модели с разной производительностью.
"Сводный балл" (от 0 до 10) — это комплексная оценка, объединяющая качество и скорость. Чем он выше, тем лучше общий баланс модели. Рассчитывается он в 3 шага:
1. Оценка качества (0-1): Балл "Качество" (от 1 до 9.9) приводится к шкале от 0 до 1, где худшая модель получает 0, а лучшая — 1.
2. Оценка скорости (0-1): Чтобы справедливо оценить скорость, мы используем логарифм времени
log(Время). Это позволяет сгладить огромный разброс. Затем эта логарифмическая шкала инвертируется (чтобы меньшее время давало больший балл) и также приводится к шкале от 0 до 1.3. Итоговый балл: Финальный рейтинг рассчитывается как взвешенное среднее с приоритетом на качество:
Итоговый балл = (Оценка качества * 0.6 + Оценка скорости * 0.4) * 10---
### 📜 Абсолютный и финальный рейтинг (Все модели и системы)
Главная таблица нашего исследования видна на картинке, данные в ней отсортированы по качеству.
* — запуски, где GPU использовался неэффективно (показатели скорости уровня CPU).*
---
### 🏆🏆🏆 Победители 🏆🏆🏆
#### Для системы с GPU (Windows, RTX 3060):
* Победитель: Llama 3 8B (Q4)
* Вердикт: Абсолютный чемпион по эффективности. Обеспечивает почти максимальное качество при самой высокой скорости (5,05 сек). Это идеальный выбор для быстрой работы.
#### Для системы с CPU (Linux Server):
* Победитель: 🥇 Llama 3 8B (Q4)
* Вердикт: Лучший баланс для "чистого" CPU. Хотя
Qwen2 7B немного быстрее (на 0.7 секунды), Llama 3 предлагает заметно более высокое качество (9.2 против 8.8). Такой минимальный проигрыш в скорости абсолютно оправдан приростом в точности и надежности. Qwen2 7B остается лучшим выбором, если важна абсолютная максимальная скорость обработки.Главный урок всего исследования: Не доверяйте общим бенчмаркам! Только тесты на собственном "железе" и своих задачах показывают истинную картину, выявляя программные аномалии и находя реальных, а не теоретических, чемпионов.
Пост: https://t.me/ai_training_ai/31
Обучение ИИ - AI Traning
2025-10-04 14:37:42
(изм. 2025-10-04 21:22:35)
### Пост 3: Тест локальных LLM.
🤖 Большой тест локальных LLM. Часть 3: CPU-сервер и финальные выводы.
В прошлый раз мы увидели, как программные особенности могут "сломать" производительность даже на мощном GPU. Чтобы выяснить истинную скорость моделей, я перенес тесты на Linux-сервер (окружение на базе AlmaLinux) с процессором AMD Ryzen 7 3700X, без видеокарты. Теперь все в равных условиях.
⚙️ Результаты на "чистом" CPU
На этот раз обошлось без сюрпризов. Производительность моделей выстроилась в "классическом" порядке:
1. Phi-3 (mini) оказалась самой быстрой (~40 сек/объявление), что логично для самой маленькой модели. 2. Qwen2 7B и Llama 3 8B (Q4) заняли второе и третье место (~44-45 сек), показав себя самыми эффективными из высококачественных моделей.
3. Более "тяжелые" версии, как Llama 3 (Q8) и FP16, оказались значительно медленнее, что доказало важность квантизации для CPU.
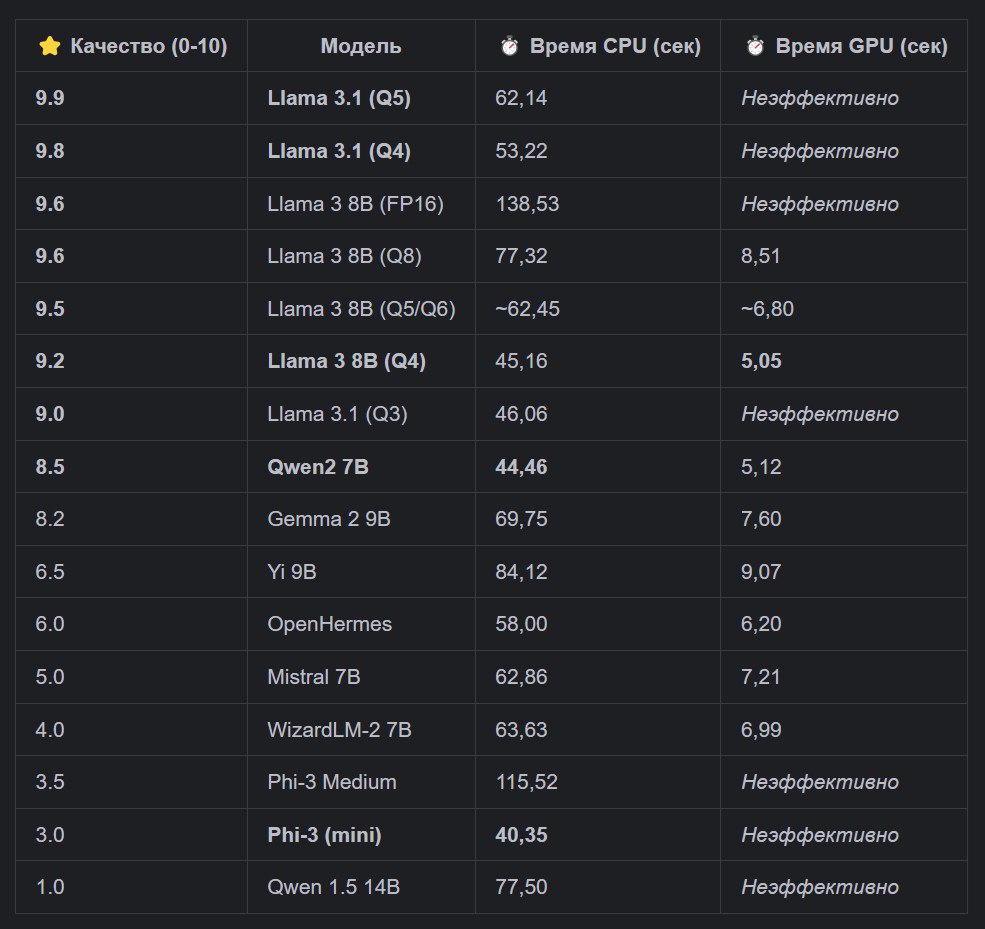
### 🏆 Финальный вердикт и рекомендации
Собрав воедино все данные по качеству, скорости на GPU и скорости на CPU, мы можем дать окончательные рекомендации.
#### Для Windows PC с GPU (быстрая работа):
* Победитель: 🥇 llama3:8b (стандартная Q4). * Почему: Абсолютный чемпион по эффективности. Обеспечивает почти максимальное качество (9.2/10) при самой высокой скорости (~5 сек). #### Для Linux Server на CPU (фоновая обработка): * Победитель: 🥇 qwen2:7b. * Почему: Оказалась самой быстрой из моделей с высоким качеством (~44 сек), что делает ее идеальным выбором для быстрой пакетной обработки на CPU. ### 📜 Итоговая "мастер-таблица" Полная картина нашего исследования отображена на картинке поста, данные в ней отсортированны по качеству. --- Заключение: Это исследование доказало: нельзя слепо доверять общим бенчмаркам. Только тесты на собственном "железе" и своих задачах показывают истинную картину. Мы не просто нашли лучшую модель, а создали систему для объективной оценки и теперь точно знаем, какой инструмент для какой работы подходит лучше всего.
🤖 Большой тест локальных LLM. Часть 3: CPU-сервер и финальные выводы.
В прошлый раз мы увидели, как программные особенности могут "сломать" производительность даже на мощном GPU. Чтобы выяснить истинную скорость моделей, я перенес тесты на Linux-сервер (окружение на базе AlmaLinux) с процессором AMD Ryzen 7 3700X, без видеокарты. Теперь все в равных условиях.
⚙️ Результаты на "чистом" CPU
На этот раз обошлось без сюрпризов. Производительность моделей выстроилась в "классическом" порядке:
1. Phi-3 (mini) оказалась самой быстрой (~40 сек/объявление), что логично для самой маленькой модели. 2. Qwen2 7B и Llama 3 8B (Q4) заняли второе и третье место (~44-45 сек), показав себя самыми эффективными из высококачественных моделей.
3. Более "тяжелые" версии, как Llama 3 (Q8) и FP16, оказались значительно медленнее, что доказало важность квантизации для CPU.
### 🏆 Финальный вердикт и рекомендации
Собрав воедино все данные по качеству, скорости на GPU и скорости на CPU, мы можем дать окончательные рекомендации.
#### Для Windows PC с GPU (быстрая работа):
* Победитель: 🥇 llama3:8b (стандартная Q4). * Почему: Абсолютный чемпион по эффективности. Обеспечивает почти максимальное качество (9.2/10) при самой высокой скорости (~5 сек). #### Для Linux Server на CPU (фоновая обработка): * Победитель: 🥇 qwen2:7b. * Почему: Оказалась самой быстрой из моделей с высоким качеством (~44 сек), что делает ее идеальным выбором для быстрой пакетной обработки на CPU. ### 📜 Итоговая "мастер-таблица" Полная картина нашего исследования отображена на картинке поста, данные в ней отсортированны по качеству. --- Заключение: Это исследование доказало: нельзя слепо доверять общим бенчмаркам. Только тесты на собственном "железе" и своих задачах показывают истинную картину. Мы не просто нашли лучшую модель, а создали систему для объективной оценки и теперь точно знаем, какой инструмент для какой работы подходит лучше всего.
Пост: https://t.me/ai_training_ai/30
Обучение ИИ - AI Traning
2025-10-04 14:28:43
(изм. 2025-10-04 14:40:02)
### Пост 2: Тест локальных LLM
🤖 Большой тест локальных LLM. Часть 2: Битва на GPU и первый сюрприз.
Настало время "гонки"! Я запустил наш скрипт на основной рабочей машине (Windows, Ryzen 9 9900X + NVIDIA RTX 3060 12 ГБ). Ожидание было простое: чем меньше модель, тем она быстрее. Но реальность оказалась куда интереснее.
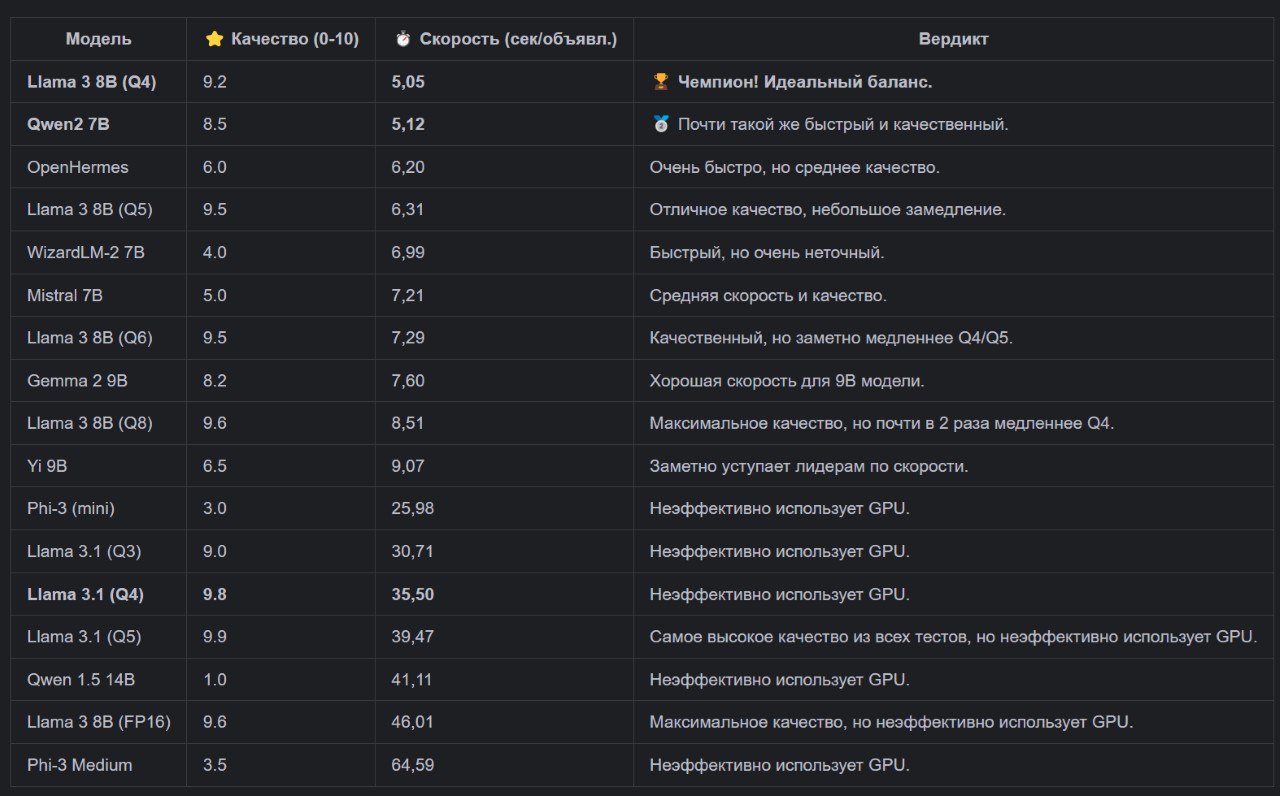
Как видно из таблицы ниже, две модели вырвались далеко вперед, а некоторые новые и теоретически мощные модели показали аномально низкую скорость.
### 📊 Итоговая таблица на картинке: Windows + GPU (RTX 3060)
*Отсортировано по скорости (от быстрой к медленной)*
🕵️♂️ Расследование: в чем причина аномалий?
После анализа стало ясно: проблема не в моделях, а в связке Ollama + Windows + Драйвер NVIDIA. Для целого ряда моделей Ollama на Windows неэффективно использует GPU, переключая основную нагрузку на медленную обработку через CPU.
Это как посадить пилота Формулы-1 (Llama 3.1) в гоночный болид (RTX 3060), но заставить его ехать по городским пробкам, вместо гоночного трека.
📊 Вердикт для GPU (Windows):
Для работы на системе с GPU победитель очевиден. Это Llama 3 8B (Q4) — она сочетает высочайшее качество и максимальную скорость. Qwen2 7B — достойная альтернатива, почти не уступающая в производительности.
---
Но что будет, если убрать GPU из уравнения и заставить всех соревноваться в равных условиях? В следующей, финальной части, мы перенесемся на Linux-сервер (помня ваши предпочтения, я подготовил его на базе AlmaLinux-совместимого окружения) и запустим тесты на "чистом" CPU. Результаты снова нас удивят!
🤖 Большой тест локальных LLM. Часть 2: Битва на GPU и первый сюрприз.
Настало время "гонки"! Я запустил наш скрипт на основной рабочей машине (Windows, Ryzen 9 9900X + NVIDIA RTX 3060 12 ГБ). Ожидание было простое: чем меньше модель, тем она быстрее. Но реальность оказалась куда интереснее.
Как видно из таблицы ниже, две модели вырвались далеко вперед, а некоторые новые и теоретически мощные модели показали аномально низкую скорость.
### 📊 Итоговая таблица на картинке: Windows + GPU (RTX 3060)
*Отсортировано по скорости (от быстрой к медленной)*
🕵️♂️ Расследование: в чем причина аномалий?
После анализа стало ясно: проблема не в моделях, а в связке Ollama + Windows + Драйвер NVIDIA. Для целого ряда моделей Ollama на Windows неэффективно использует GPU, переключая основную нагрузку на медленную обработку через CPU.
Это как посадить пилота Формулы-1 (Llama 3.1) в гоночный болид (RTX 3060), но заставить его ехать по городским пробкам, вместо гоночного трека.
📊 Вердикт для GPU (Windows):
Для работы на системе с GPU победитель очевиден. Это Llama 3 8B (Q4) — она сочетает высочайшее качество и максимальную скорость. Qwen2 7B — достойная альтернатива, почти не уступающая в производительности.
---
Но что будет, если убрать GPU из уравнения и заставить всех соревноваться в равных условиях? В следующей, финальной части, мы перенесемся на Linux-сервер (помня ваши предпочтения, я подготовил его на базе AlmaLinux-совместимого окружения) и запустим тесты на "чистом" CPU. Результаты снова нас удивят!
Пост: https://t.me/ai_training_ai/29

Обучение ИИ - AI Traning
2025-10-04 14:00:24
(изм. 2025-10-06 10:33:47)
### Пост 1: Тест локальных LLM
🤖Как я заставил нейросеть работать на меня: Большой тест локальных LLM. Часть 1: Подготовка.
Всем привет! Надоело вручную копировать данные из объявлений о недвижимости? Мне тоже. Я решил автоматизировать этот процесс с помощью локальных нейросетей — чтобы было бесплатно, приватно и под моим полным контролем. Так начался мой проект по созданию идеального парсера.
🎯Цель: Научить нейросеть читать объявления на смеси русского и узбекского и возвращать чистый, структурированный JSON.
Проект: mulk.top.
1️⃣ "Техническое задание" для ИИ: Промпт
Главное оружие в работе с LLM — это промпт. Я не стал мелочиться и создал подробнейший "регламент" в файле prompt.txt. В него вошли:
* Более 30 детальных правил для извлечения каждого поля.
* Обработка форматов вроде 3/5/9 (комнаты/этаж/этажность).
* Распознавание узбекских слов (Manzili, Xonalar, Narxi).
* Правила для цен в у.е., $ и млн сум.
Это не просто просьба, а настоящий приказ для модели, как именно структурировать данные.
2️⃣ "Арена" для битвы: Скрипт и Окружение
Для проведения честного "чемпионата" я подготовил тестовый стенд:
* Ollama: для быстрого и удобного запуска моделей локально.
* Python + asyncio: для написания асинхронного скрипта, который одновременно отправляет одно и то же объявление всем моделям-участникам.
* config.json: чтобы легко менять список моделей и тестовые данные, не трогая код. * Сохранение результатов: скрипт автоматически генерирует детальные JSON-отчеты и общую Excel-таблицу со статистикой. 3️⃣ "Бойцы": Первые участники
Для старта я выбрал самых известных "бойцов" разного калибра: от тяжеловеса Llama 3 8B до легковеса Phi-3:
* llama3.1:8b;
* llama3.1:8b-instruct-q3_K_M;
* llama3.1:8b-instruct-q5_K_M;
* llama3:8b-instruct-q5_K_M;
* llama3:8b-instruct-q6_K;
* llama3:8b-instruct-q8_0;
* llama3:8b-instruct-fp16;
* llama3:8b;
* gemma2:9b;
* phi3:medium;
* wizardlm2:7b;
* yi:9b;
* openhermes:7b-mistral-v2.5-q4_0;
* mistral:7b;
* phi3;
* qwen:14b;
* qwen2:7b
---
Подготовка завершена, скрипт готов к запуску. В следующей части мы запустим наш "чемпионат" на мощной машине с GPU и получим первые, совершенно неожиданные результаты. Будет интересно! 🔥
🤖Как я заставил нейросеть работать на меня: Большой тест локальных LLM. Часть 1: Подготовка.
Всем привет! Надоело вручную копировать данные из объявлений о недвижимости? Мне тоже. Я решил автоматизировать этот процесс с помощью локальных нейросетей — чтобы было бесплатно, приватно и под моим полным контролем. Так начался мой проект по созданию идеального парсера.
🎯Цель: Научить нейросеть читать объявления на смеси русского и узбекского и возвращать чистый, структурированный JSON.
Проект: mulk.top.
1️⃣ "Техническое задание" для ИИ: Промпт
Главное оружие в работе с LLM — это промпт. Я не стал мелочиться и создал подробнейший "регламент" в файле prompt.txt. В него вошли:
* Более 30 детальных правил для извлечения каждого поля.
* Обработка форматов вроде 3/5/9 (комнаты/этаж/этажность).
* Распознавание узбекских слов (Manzili, Xonalar, Narxi).
* Правила для цен в у.е., $ и млн сум.
Это не просто просьба, а настоящий приказ для модели, как именно структурировать данные.
2️⃣ "Арена" для битвы: Скрипт и Окружение
Для проведения честного "чемпионата" я подготовил тестовый стенд:
* Ollama: для быстрого и удобного запуска моделей локально.
* Python + asyncio: для написания асинхронного скрипта, который одновременно отправляет одно и то же объявление всем моделям-участникам.
* config.json: чтобы легко менять список моделей и тестовые данные, не трогая код. * Сохранение результатов: скрипт автоматически генерирует детальные JSON-отчеты и общую Excel-таблицу со статистикой. 3️⃣ "Бойцы": Первые участники
Для старта я выбрал самых известных "бойцов" разного калибра: от тяжеловеса Llama 3 8B до легковеса Phi-3:
* llama3.1:8b;
* llama3.1:8b-instruct-q3_K_M;
* llama3.1:8b-instruct-q5_K_M;
* llama3:8b-instruct-q5_K_M;
* llama3:8b-instruct-q6_K;
* llama3:8b-instruct-q8_0;
* llama3:8b-instruct-fp16;
* llama3:8b;
* gemma2:9b;
* phi3:medium;
* wizardlm2:7b;
* yi:9b;
* openhermes:7b-mistral-v2.5-q4_0;
* mistral:7b;
* phi3;
* qwen:14b;
* qwen2:7b
---
Подготовка завершена, скрипт готов к запуску. В следующей части мы запустим наш "чемпионат" на мощной машине с GPU и получим первые, совершенно неожиданные результаты. Будет интересно! 🔥
Пост: https://t.me/ai_training_ai/28

Обучение ИИ - AI Traning
2025-08-09 11:24:25
(изм. 2025-09-19 22:04:10)
💡 Разбираемся в лимитах токенов у нейросети
📦 Что такое *context window*?
Запрос — это всё, что модель получает и обрабатывает за один цикл:
- твой текущий вопрос или инструкция
- предыдущая переписка (если она передаётся)
- вложенные файлы или тексты
- системные подсказки и инструкции
Пример:
- ~300–320 тыс. слов на английском
- ~200–250 тыс. слов на русском
✍ Что такое *max output tokens*?
Например, при
- Английский: ~512 000 символов (~90–100 тыс. слов, ~180–200 стр. А4)
- Русский: ~320 000 символов (~50–55 тыс. слов, ~110–120 стр. А4)
🔍 Как это работает вместе
-
-
- Если контекст почти полностью занят входными данными, на ответ останется мало места.
📊 Пример:
- Входные данные (контекст): 350 000 токенов
- Лимит окна: 400 000 токенов
- Остаётся на ответ: 50 000 токенов
(даже если
⚡ Запомни:
1. Чем длиннее твой запрос и история переписки, тем меньше места остаётся для ответа.
2. Чтобы получить максимально длинный ответ — подавай меньше исходных данных.
3. На русском тексты «весят» в токенах больше, чем на английском.
📦 Что такое *context window*?
context window — это максимальный объём данных, который модель может *одновременно держать в памяти* в одном запросе.Запрос — это всё, что модель получает и обрабатывает за один цикл:
- твой текущий вопрос или инструкция
- предыдущая переписка (если она передаётся)
- вложенные файлы или тексты
- системные подсказки и инструкции
Пример:
400 000 context window → модель может обработать примерно:- ~300–320 тыс. слов на английском
- ~200–250 тыс. слов на русском
✍ Что такое *max output tokens*?
max output tokens — это лимит на объём ответа за один запрос.Например, при
128 000 max output tokens модель способна выдать:- Английский: ~512 000 символов (~90–100 тыс. слов, ~180–200 стр. А4)
- Русский: ~320 000 символов (~50–55 тыс. слов, ~110–120 стр. А4)
🔍 Как это работает вместе
-
context window = ВХОД + ВЫХОД-
max output tokens = только ВЫХОД- Если контекст почти полностью занят входными данными, на ответ останется мало места.
📊 Пример:
- Входные данные (контекст): 350 000 токенов
- Лимит окна: 400 000 токенов
- Остаётся на ответ: 50 000 токенов
(даже если
max output tokens = 128 000)⚡ Запомни:
1. Чем длиннее твой запрос и история переписки, тем меньше места остаётся для ответа.
2. Чтобы получить максимально длинный ответ — подавай меньше исходных данных.
3. На русском тексты «весят» в токенах больше, чем на английском.
❤ 59
Пост: https://t.me/ai_training_ai/27

Обучение ИИ - AI Traning
2025-08-09 11:03:33
(изм. 2025-08-09 11:03:36)
🚀 Новая эпоха — OpenAI запускает GPT-5!
7 августа 2025 года OpenAI представила GPT-5 — свою самую мощную и продвинутую языковую модель, теперь доступную всем пользователям ChatGPT — включая бесплатных.
🔥 Что особенного в GPT-5?
- Интеллект «на уровне PhD» — по словам Сэма Альтмана, GPT-5 превосходит предыдущие модели по скорости, точности и широте возможностей.
- Гибридная архитектура с маршрутизатором — система включает лёгкие модели (
- Сокращение ошибок:
- −44 % фактических ошибок в
- −78 % ошибок в
- −69 % снижения «подлизывания»
- −2× меньше попыток обмана
- Улучшения для кодинга — лучше на SWEBench, меньше токенов и API-вызовов.
⚙️ Технические характеристики
- Окно контекста (API): до
- Вывод: до
- Контекст в чате:
- Free — 8K
- Plus — 32K
- Pro / Enterprise — 128K
- Новые API-параметры:
-
-
- Безопасность: AES-256, TLS 1.2+, SOC 2, GDPR, CCPA, без обучения на пользовательских данных по умолчанию
- Ввод: текст + изображения
- Стоимость API:
-
-
-
🗣 Что говорят пользователи?
*“GPT-5 — самая умная модель для кодинга, которую мы использовали... ловит сложные баги, управляет многотуровыми агентами”* — Михаэль Трулл (Cursor).
🎯 Итог
GPT-5 — это не просто обновление, а качественный скачок:
умный роутинг, гигантское окно контекста, гибкие инструменты для разработчиков, максимальная безопасность и высокая точность.
💬 Готовы попробовать? Делитесь в комментариях, что у вас получилось!
7 августа 2025 года OpenAI представила GPT-5 — свою самую мощную и продвинутую языковую модель, теперь доступную всем пользователям ChatGPT — включая бесплатных.
🔥 Что особенного в GPT-5?
- Интеллект «на уровне PhD» — по словам Сэма Альтмана, GPT-5 превосходит предыдущие модели по скорости, точности и широте возможностей.
- Гибридная архитектура с маршрутизатором — система включает лёгкие модели (
gpt-5-main, gpt-5-mini) и глубокие модели для рассуждений (gpt-5-thinking, gpt-5-thinking-mini, gpt-5-thinking-nano, gpt-5-thinking-pro), между которыми роутер переключается в реальном времени. - Сокращение ошибок:
- −44 % фактических ошибок в
gpt-5-main - −78 % ошибок в
gpt-5-thinking - −69 % снижения «подлизывания»
- −2× меньше попыток обмана
- Улучшения для кодинга — лучше на SWEBench, меньше токенов и API-вызовов.
⚙️ Технические характеристики
- Окно контекста (API): до
400 000 токенов - Вывод: до
128 000 токенов - Контекст в чате:
- Free — 8K
- Plus — 32K
- Pro / Enterprise — 128K
- Новые API-параметры:
-
verbosity — уровень детализации (низкий, средний, высокий) -
reasoning_effort — глубина рассуждений - Безопасность: AES-256, TLS 1.2+, SOC 2, GDPR, CCPA, без обучения на пользовательских данных по умолчанию
- Ввод: текст + изображения
- Стоимость API:
-
gpt-5: $1.25 / млн входных токенов, $10 / млн выходных -
gpt-5-mini: $0.25 / $2 -
gpt-5-nano: $0.05 / $0.40 🗣 Что говорят пользователи?
*“GPT-5 — самая умная модель для кодинга, которую мы использовали... ловит сложные баги, управляет многотуровыми агентами”* — Михаэль Трулл (Cursor).
🎯 Итог
GPT-5 — это не просто обновление, а качественный скачок:
умный роутинг, гигантское окно контекста, гибкие инструменты для разработчиков, максимальная безопасность и высокая точность.
💬 Готовы попробовать? Делитесь в комментариях, что у вас получилось!
Пост: https://t.me/ai_training_ai/26
Обучение ИИ - AI Traning
2025-06-22 22:33:44
(изм. 2025-06-22 22:34:15)
Пост: https://t.me/ai_training_ai/25
Обучение ИИ - AI Traning
2025-06-22 22:33:44
(изм. 2025-06-22 22:33:47)
Выбор ИИ модели под конкретный проект, когда какую модель выбирать
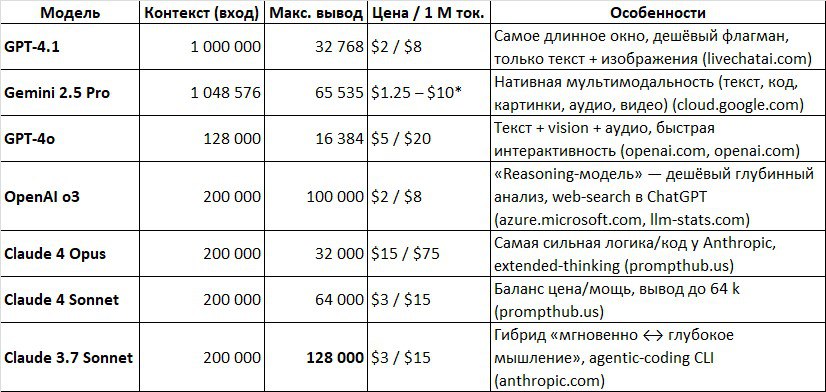
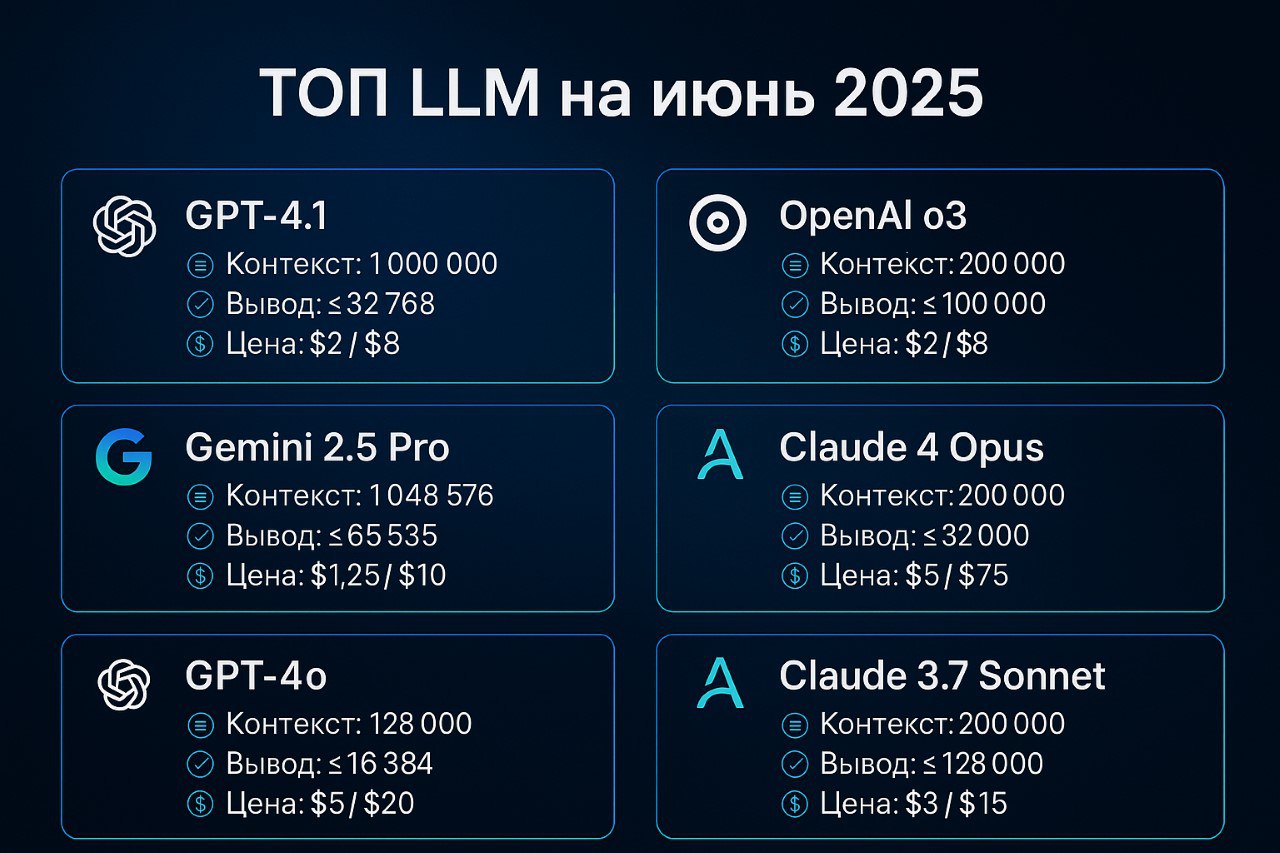
🚀 Сводка топ-LLM (июнь 2025)
🌐 GPT-4.1
▪️ Контекст: 1 000 000 т
▪️ Вывод: ≤ 32 768 т
▪️ Цена: $2 / $8 (за 1 M т)
▪️ Лучший выбор для гигантских корпусов текста
🛰 Gemini 2.5 Pro
▪️ Контекст: 1 048 576 т
▪️ Вывод: ≤ 65 535 т
▪️ Цена: $1.25 / $10
▪️ Нативная мультимодальность (текст + изобр + аудио)
⚡ GPT-4o
▪️ Контекст: 128 000 т
▪️ Вывод: ≤ 16 384 т
▪️ Цена: $5 / $20
▪️ Vision + Voice, минимальная задержка
🧠 OpenAI o3
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 100 000 т
▪️ Цена: $2 / $8
▪️ Дешёвое «глубокое» рассуждение
🏆 Claude 4 Opus
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 32 000 т
▪️ Цена: $15 / $75
▪️ Максимальная точность логики и кода
💡 Claude 4 Sonnet
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 64 000 т
▪️ Цена: $3 / $15
▪️ Лучший баланс цена / мощь
📖 Claude 3.7 Sonnet
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 128 000 т
▪️ Цена: $3 / $15
▪️ Рекордный вывод 128 k
---
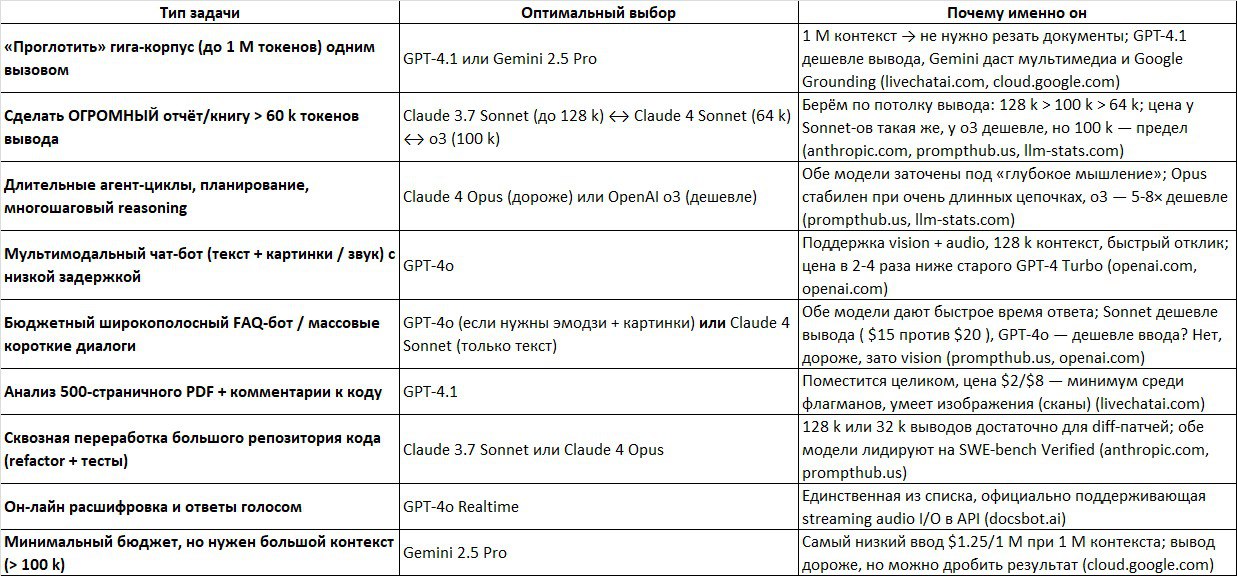
### 💼 Когда что брать
🔹 Нужен 1 М контекста → *GPT-4.1* или *Gemini 2.5 Pro*
🔹 Гигантский вывод (> 60 k) → *Claude 3.7 Sonnet* (128 k) → *o3* (100 k) → *Claude 4 Sonnet* (64 k)
🔹 Сложный многошаговый reasoning → *Claude 4 Opus* (премиум) или *o3* (эконом)
🔹 Мультимедийный чат-бот → *GPT-4o*
🔹 Массовый FAQ-бот → *GPT-4o* (если нужны картинки) / *Claude 4 Sonnet* (только текст)
🔹 Анализ 500-страничного PDF → *GPT-4.1*
🔹 Рефакторинг большого репо → *Claude 3.7 Sonnet* или *Claude 4 Opus*
🔹 Speech-to-text / Voice-ответы → *GPT-4o Realtime*
🔹 Мин. бюджет при > 100 k контекста → *Gemini 2.5 Pro*
---
⚙️ Лайфхаки экономии
1. Кэшируйте неизменный prompt — у OpenAI -75 %, у Anthropic -90 %.
2. Дробите вывод на главы по 10-15 k: меньше обрывов, дешевле перезапуск.
3. Явно задавайте
4. Помните про Актуальность основной базы знаний (knowledge cut-off): GPT знает до 06/24, Claude — до 03/25, Gemini — до 01/25.
----
Контакты: https://t.me/ai_training_ai/3
🚀 Сводка топ-LLM (июнь 2025)
🌐 GPT-4.1
▪️ Контекст: 1 000 000 т
▪️ Вывод: ≤ 32 768 т
▪️ Цена: $2 / $8 (за 1 M т)
▪️ Лучший выбор для гигантских корпусов текста
🛰 Gemini 2.5 Pro
▪️ Контекст: 1 048 576 т
▪️ Вывод: ≤ 65 535 т
▪️ Цена: $1.25 / $10
▪️ Нативная мультимодальность (текст + изобр + аудио)
⚡ GPT-4o
▪️ Контекст: 128 000 т
▪️ Вывод: ≤ 16 384 т
▪️ Цена: $5 / $20
▪️ Vision + Voice, минимальная задержка
🧠 OpenAI o3
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 100 000 т
▪️ Цена: $2 / $8
▪️ Дешёвое «глубокое» рассуждение
🏆 Claude 4 Opus
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 32 000 т
▪️ Цена: $15 / $75
▪️ Максимальная точность логики и кода
💡 Claude 4 Sonnet
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 64 000 т
▪️ Цена: $3 / $15
▪️ Лучший баланс цена / мощь
📖 Claude 3.7 Sonnet
▪️ Контекст: 200 000 т
▪️ Вывод: ≤ 128 000 т
▪️ Цена: $3 / $15
▪️ Рекордный вывод 128 k
---
### 💼 Когда что брать
🔹 Нужен 1 М контекста → *GPT-4.1* или *Gemini 2.5 Pro*
🔹 Гигантский вывод (> 60 k) → *Claude 3.7 Sonnet* (128 k) → *o3* (100 k) → *Claude 4 Sonnet* (64 k)
🔹 Сложный многошаговый reasoning → *Claude 4 Opus* (премиум) или *o3* (эконом)
🔹 Мультимедийный чат-бот → *GPT-4o*
🔹 Массовый FAQ-бот → *GPT-4o* (если нужны картинки) / *Claude 4 Sonnet* (только текст)
🔹 Анализ 500-страничного PDF → *GPT-4.1*
🔹 Рефакторинг большого репо → *Claude 3.7 Sonnet* или *Claude 4 Opus*
🔹 Speech-to-text / Voice-ответы → *GPT-4o Realtime*
🔹 Мин. бюджет при > 100 k контекста → *Gemini 2.5 Pro*
---
⚙️ Лайфхаки экономии
1. Кэшируйте неизменный prompt — у OpenAI -75 %, у Anthropic -90 %.
2. Дробите вывод на главы по 10-15 k: меньше обрывов, дешевле перезапуск.
3. Явно задавайте
max_tokens, чтобы не платить за «лишние» токены. 4. Помните про Актуальность основной базы знаний (knowledge cut-off): GPT знает до 06/24, Claude — до 03/25, Gemini — до 01/25.
----
Контакты: https://t.me/ai_training_ai/3
Пост: https://t.me/ai_training_ai/24
Обучение ИИ - AI Traning
2025-06-22 22:33:44
(изм. 2025-07-13 14:41:42)
❤ 1
Пост: https://t.me/ai_training_ai/22
Обучение ИИ - AI Traning
2025-06-11 06:19:45
(изм. 2025-06-11 07:49:15)
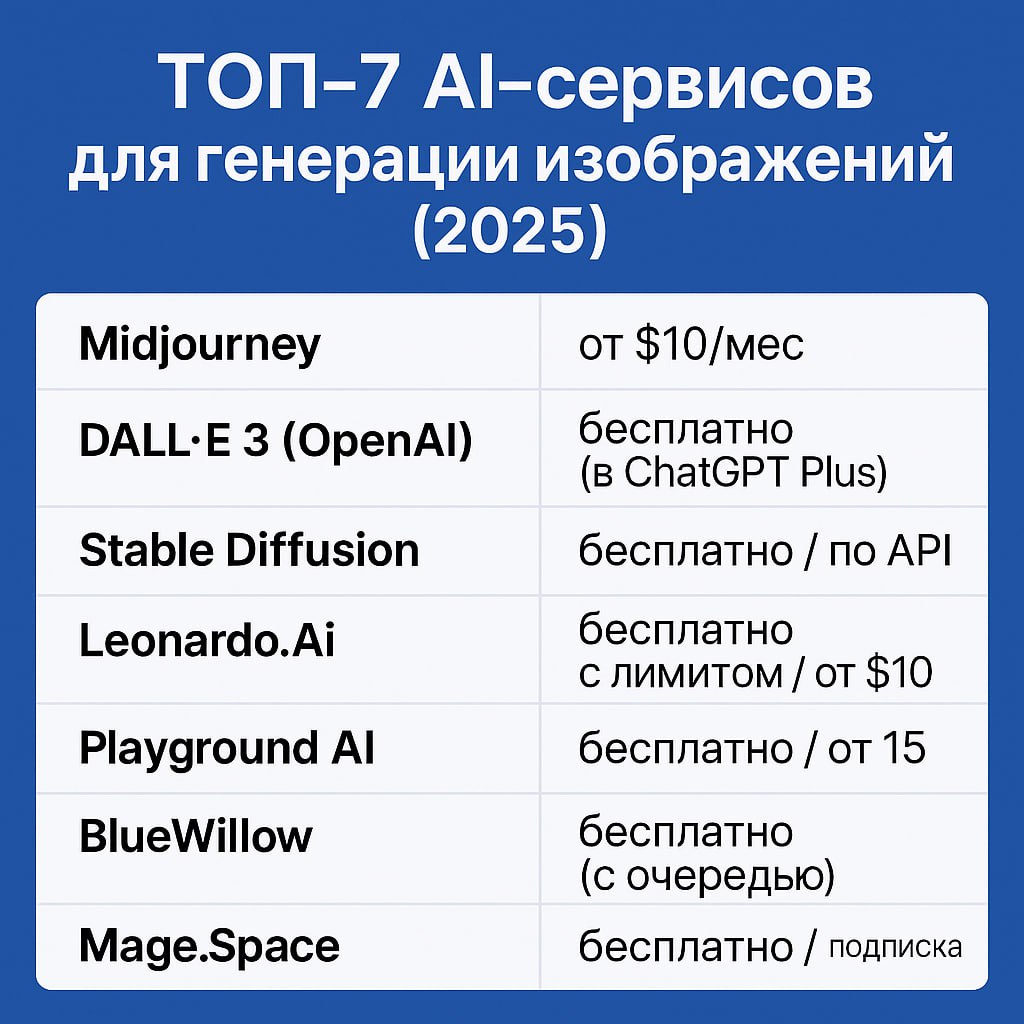
## 🔝 ТОП-7 ИИ-сервисов для генерации изображений (2025)
Вот список лучших альтернатив Midjourney для генерации изображений с помощью ИИ — их особенности, цены, плюсы и минусы:
---
### 1. Midjourney
🎨 Стильные, художественные иллюстрации
💲 от $10/мес
➕ Высокое качество, узнаваемый стиль
➖ Нет бесплатной версии
---
### 2. DALL·E 3 (OpenAI)
🤖 Глубокая интеграция с ChatGPT
💲 Бесплатно (в ChatGPT Plus)
➕ Удобно, прямо в чате
➖ Меньше свободы в деталях и стилях
---
### 3. Stable Diffusion (SDXL)
🖥 Open-source, локальный запуск
💲 Бесплатно / по API
➕ Полный контроль, офлайн-использование
➖ Требуются тех. навыки для установки
---
### 4. Leonardo.Ai
🎭 Много стилей, можно использовать коммерчески
💲 Бесплатно с лимитом / от $10
➕ Удобный интерфейс, свой ИИ + SD
➖ Очереди, много фич платные
---
### 5. Playground AI
🧩 Комбинация SD и DALL·E 2
💲 Бесплатно / от $15
➕ Онлайн-редактор, inpainting, стили
➖ Ограничения в бесплатной версии
---
### 6. BlueWillow
💬 Дискорд-бот, похож на Midjourney
💲 Бесплатно (с очередью)
➕ Лёгкий старт, Midjourney-стиль
➖ Мало кастомизации, долгое ожидание
---
### 7. Mage.Space
🌐 Веб-интерфейс для SDXL
💲 Бесплатно / подписка
➕ Без регистрации, быстрый старт
➖ Мало настроек, качество ниже Midjourney
---
## 💡 Рекомендации по выбору:
🎨 Иллюстрации в авторском стиле → Midjourney, Leonardo.Ai
📥 Бесплатный запуск на ПК → Stable Diffusion
⚙️ Гибкая настройка → SDXL + WebUI (AUTOMATIC1111)
🧠 Встроено в чат → DALL·E 3 (ChatGPT Plus)
📱 Простота и интерфейс → Playground AI, Mage.Space
🚀 Быстрый старт без затрат → BlueWillow, Mage.Space
Вот список лучших альтернатив Midjourney для генерации изображений с помощью ИИ — их особенности, цены, плюсы и минусы:
---
### 1. Midjourney
🎨 Стильные, художественные иллюстрации
💲 от $10/мес
➕ Высокое качество, узнаваемый стиль
➖ Нет бесплатной версии
---
### 2. DALL·E 3 (OpenAI)
🤖 Глубокая интеграция с ChatGPT
💲 Бесплатно (в ChatGPT Plus)
➕ Удобно, прямо в чате
➖ Меньше свободы в деталях и стилях
---
### 3. Stable Diffusion (SDXL)
🖥 Open-source, локальный запуск
💲 Бесплатно / по API
➕ Полный контроль, офлайн-использование
➖ Требуются тех. навыки для установки
---
### 4. Leonardo.Ai
🎭 Много стилей, можно использовать коммерчески
💲 Бесплатно с лимитом / от $10
➕ Удобный интерфейс, свой ИИ + SD
➖ Очереди, много фич платные
---
### 5. Playground AI
🧩 Комбинация SD и DALL·E 2
💲 Бесплатно / от $15
➕ Онлайн-редактор, inpainting, стили
➖ Ограничения в бесплатной версии
---
### 6. BlueWillow
💬 Дискорд-бот, похож на Midjourney
💲 Бесплатно (с очередью)
➕ Лёгкий старт, Midjourney-стиль
➖ Мало кастомизации, долгое ожидание
---
### 7. Mage.Space
🌐 Веб-интерфейс для SDXL
💲 Бесплатно / подписка
➕ Без регистрации, быстрый старт
➖ Мало настроек, качество ниже Midjourney
---
## 💡 Рекомендации по выбору:
🎨 Иллюстрации в авторском стиле → Midjourney, Leonardo.Ai
📥 Бесплатный запуск на ПК → Stable Diffusion
⚙️ Гибкая настройка → SDXL + WebUI (AUTOMATIC1111)
🧠 Встроено в чат → DALL·E 3 (ChatGPT Plus)
📱 Простота и интерфейс → Playground AI, Mage.Space
🚀 Быстрый старт без затрат → BlueWillow, Mage.Space
Пост: https://t.me/ai_training_ai/21

Обучение ИИ - AI Traning
2025-06-11 06:16:11
(изм. 2025-06-11 06:18:59)
🚀 Срочные новости от OpenAI: o3 дешевле на 80%, и новая модель o3-pro уже в API!
OpenAI сегодня объявила о кардинальных изменениях в своей линейке моделей, сделав их еще доступнее и мощнее.
### 💰 o3 стал на 80% дешевле!
Стоимость популярной модели o3 была значительно снижена благодаря оптимизации. Это та же самая модель, но по новой, невероятно выгодной цене:
* $2 / 1 млн входных токенов
* $8 / 1 млн выходных токенов
OpenAI рекомендует использовать o3 для кодинга (теперь цена такая же, как у GPT-4.1, и дешевле, чем у GPT-4o!), а также для задач, требующих вызова функций, работы с инструментами и точного следования инструкциям.
---
### ✨ o3-pro: новая планка мощности
Для самых сложных и требовательных задач OpenAI выпустила o3-pro. Эта модель использует больше вычислительных ресурсов, чтобы "думать усерднее" и предоставлять надежные решения.
И самое главное — цена! Модель o3-pro на 87% дешевле своего предшественника o1-pro:
* $20 / 1 млн входных токенов
* $80 / 1 млн выходных токенов
Ключевые особенности o3-pro:
* Поддержка изображений в качестве входных данных 🖼
* Вызов функций и Structured Outputs.
* Доступна в API под именем
⚠️ Важно: Запросы к o3-pro могут выполняться несколько минут. Чтобы избежать тайм-аутов, OpenAI рекомендует использовать новый фоновый режим (background mode) в API.
Это отличная возможность перевести ваши проекты на более мощные и доступные модели!
🔗 *Начните тестировать o3-pro в Playground OpenAI уже сейчас.*
OpenAI сегодня объявила о кардинальных изменениях в своей линейке моделей, сделав их еще доступнее и мощнее.
### 💰 o3 стал на 80% дешевле!
Стоимость популярной модели o3 была значительно снижена благодаря оптимизации. Это та же самая модель, но по новой, невероятно выгодной цене:
* $2 / 1 млн входных токенов
* $8 / 1 млн выходных токенов
OpenAI рекомендует использовать o3 для кодинга (теперь цена такая же, как у GPT-4.1, и дешевле, чем у GPT-4o!), а также для задач, требующих вызова функций, работы с инструментами и точного следования инструкциям.
---
### ✨ o3-pro: новая планка мощности
Для самых сложных и требовательных задач OpenAI выпустила o3-pro. Эта модель использует больше вычислительных ресурсов, чтобы "думать усерднее" и предоставлять надежные решения.
И самое главное — цена! Модель o3-pro на 87% дешевле своего предшественника o1-pro:
* $20 / 1 млн входных токенов
* $80 / 1 млн выходных токенов
Ключевые особенности o3-pro:
* Поддержка изображений в качестве входных данных 🖼
* Вызов функций и Structured Outputs.
* Доступна в API под именем
o3-pro-2025-06-10.⚠️ Важно: Запросы к o3-pro могут выполняться несколько минут. Чтобы избежать тайм-аутов, OpenAI рекомендует использовать новый фоновый режим (background mode) в API.
Это отличная возможность перевести ваши проекты на более мощные и доступные модели!
🔗 *Начните тестировать o3-pro в Playground OpenAI уже сейчас.*
Пост: https://t.me/ai_training_ai/20

Обучение ИИ - AI Traning
2025-06-07 21:27:35
(изм. 2025-06-07 21:27:38)
Тестировали последние несколько месяцев ЧатГПТ, Клод и Джемини.
В основном задачи по созданию программных решений.
Задачи именно довольно сложные, в основном связанные с созданием веб проектов и сайтов на Джанго, Питоне, Flask, FastAPI.
Итог такой, на данный момент лучшим из всех в этих задачах является Google Gemini 2.5 Pro, более ранние версии Gemini были очень плохи в этих задачах.
У Claude окно контекста маленькое, вроде не более 200 тысяч токенов, и он через некоторое время в чате начинает путаться, пробовали версию 3.7, но не думаем, что в 4-ой версии что-то сильно поменялось, так как окно они не увеличили. У ChatGPT моделей тоже не больше контекстное окно, 200 тысяч или даже 64К.
А последняя модель от Гугла имеет контекст от 1 миллиона до 2 миллионов токенов, этим все и объясняется.
Но генерация картинок хорошо работает только у ChatGPT и Midjourney.
Gemini часто неверные тексты наносит, а Claude вместо картинки может сделать html или svg файл.
В основном задачи по созданию программных решений.
Задачи именно довольно сложные, в основном связанные с созданием веб проектов и сайтов на Джанго, Питоне, Flask, FastAPI.
Итог такой, на данный момент лучшим из всех в этих задачах является Google Gemini 2.5 Pro, более ранние версии Gemini были очень плохи в этих задачах.
У Claude окно контекста маленькое, вроде не более 200 тысяч токенов, и он через некоторое время в чате начинает путаться, пробовали версию 3.7, но не думаем, что в 4-ой версии что-то сильно поменялось, так как окно они не увеличили. У ChatGPT моделей тоже не больше контекстное окно, 200 тысяч или даже 64К.
А последняя модель от Гугла имеет контекст от 1 миллиона до 2 миллионов токенов, этим все и объясняется.
Но генерация картинок хорошо работает только у ChatGPT и Midjourney.
Gemini часто неверные тексты наносит, а Claude вместо картинки может сделать html или svg файл.
| Модель | Контекст | Качество кода | Генерация изображений |
| ------------------------ | --------- | ---------------------- | ------------------------- |
| **ChatGPT (o4/o4-mini)** | до 200K | стабильно, но теряется | Отлично (DALL·E) |
| **Claude 3.7** | \~200K | логика OK, но путается | HTML вместо изображений |
| **Gemini 2.5 Pro** | **до 2M** | !!!! Лидер по коду | Часто сбивается |
Пост: https://t.me/ai_training_ai/17
Обучение ИИ - AI Traning
2025-06-05 17:43:22
(изм. 2025-06-05 17:43:25)
Пост: https://t.me/ai_training_ai/15
Ответ на сообщение #10
source2.html
Обучение ИИ - AI Traning
2025-06-05 17:03:15
(изм. 2025-06-05 17:53:20)
Пост: https://t.me/ai_training_ai/14
Ответ на сообщение #10
source1.html
Обучение ИИ - AI Traning
2025-06-05 17:03:15
(изм. 2025-06-05 17:53:14)
Пост: https://t.me/ai_training_ai/12
Обучение ИИ - AI Traning
2025-06-05 16:54:28
(изм. 2025-06-05 16:54:31)
Пост: https://t.me/ai_training_ai/11
Обучение ИИ - AI Traning
2025-06-05 16:54:28
(изм. 2025-06-05 17:15:01)
Пост: https://t.me/ai_training_ai/10
Обучение ИИ - AI Traning
2025-06-05 16:54:28
(изм. 2025-06-05 17:15:17)
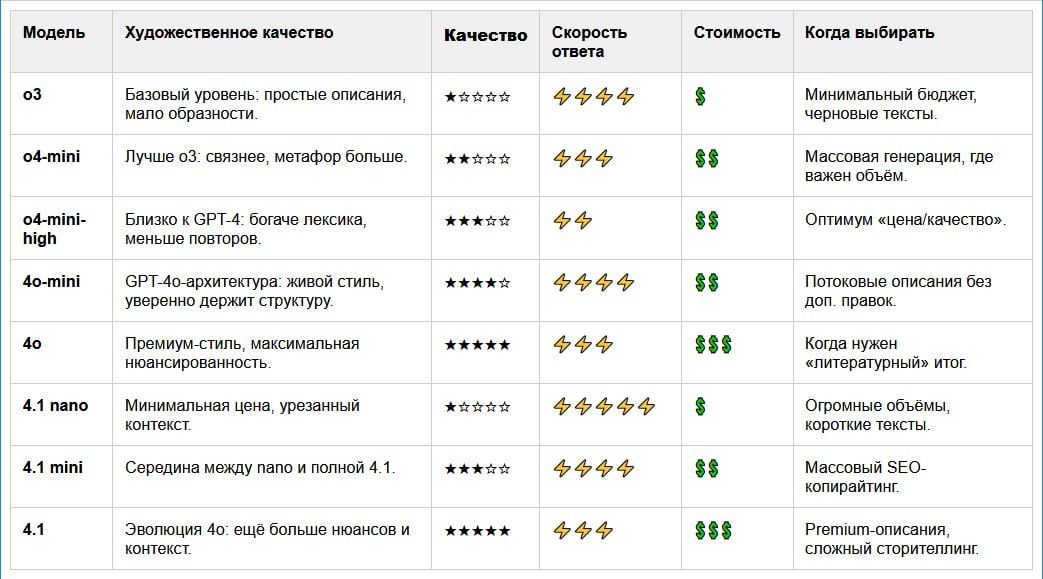
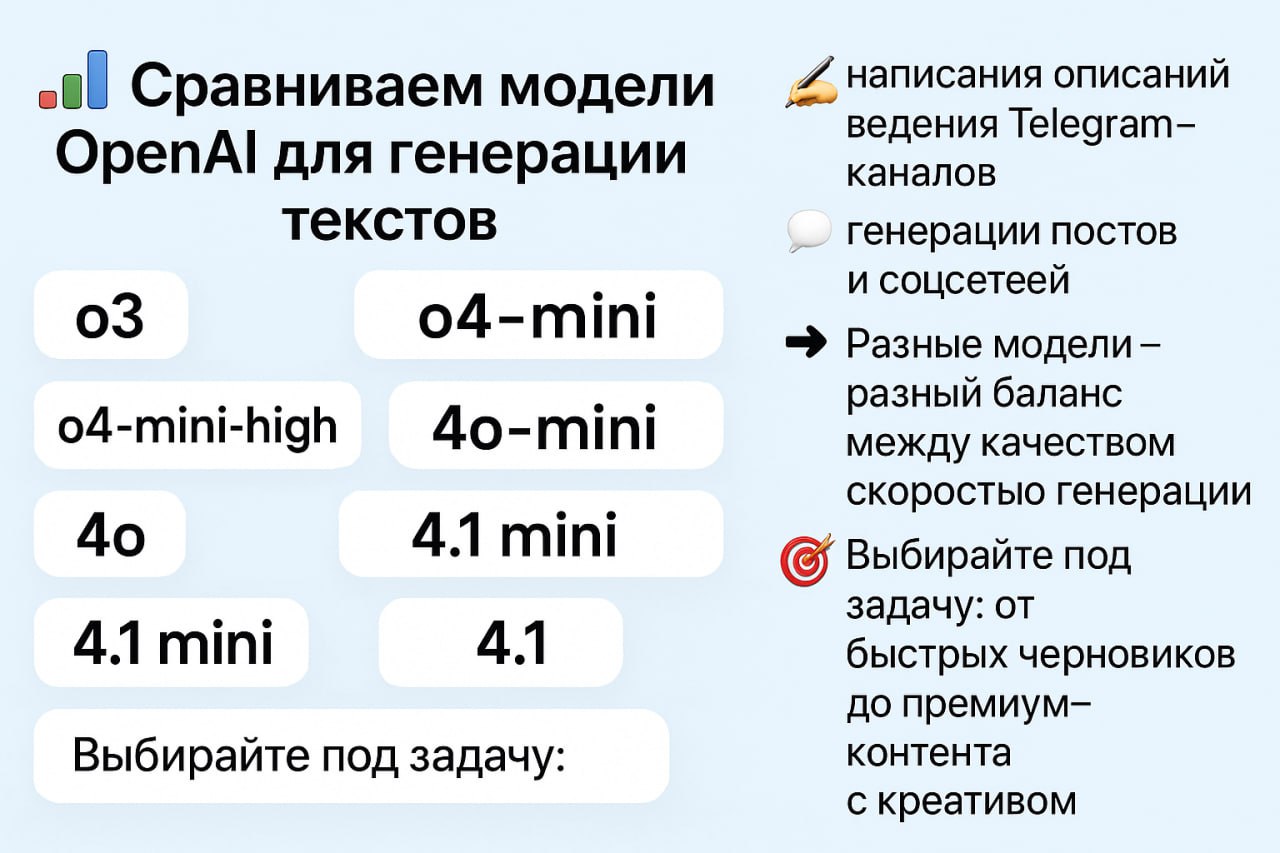
Сравниваем модели OpenAI для генерации текстов.
Какую модель лучше использовать для созданий описаний для сайта, Телеграм канала и социальных сетей?
В таблицах сравнение OpenAI ChatGPT моделей.
Чтобы не терять время на тесты, вот краткое сравнение моделей ChatGPT от OpenAI.
⚙️ В таблице ниже:
— художественное качество
— скорость ответа
— стоимость
— и когда какую модель использовать
Выбирайте оптимум под задачу: от черновиков до премиум-контента.
### 💡 Выводы по моделям ChatGPT для генерации описаний
✅ Оптимум "цена/качество"
Модели
💎 Премиум-уровень
⚡️ Максимальная скорость и поток
🎯 Рекомендация
Если бюджет ограничен —
Если нужна глубина и эффект —
Если важна скорость и объём —
### 💰 Сравнение моделей ChatGPT по цене и качеству
📉 Дешевле всего
*
*
⚖️ Оптимальный баланс
*
*
💎 Премиум-качество
*
💡 Нерациональные
*
---
### 🎯 Рекомендации:
* Поток дешёвых описаний -
* Баланс цены и читаемости -
* Стильные, глубокие тексты -
* Эксперименты, черновики, тесты -
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Какую модель лучше использовать для созданий описаний для сайта, Телеграм канала и социальных сетей?
В таблицах сравнение OpenAI ChatGPT моделей.
Чтобы не терять время на тесты, вот краткое сравнение моделей ChatGPT от OpenAI.
⚙️ В таблице ниже:
— художественное качество
— скорость ответа
— стоимость
— и когда какую модель использовать
Выбирайте оптимум под задачу: от черновиков до премиум-контента.
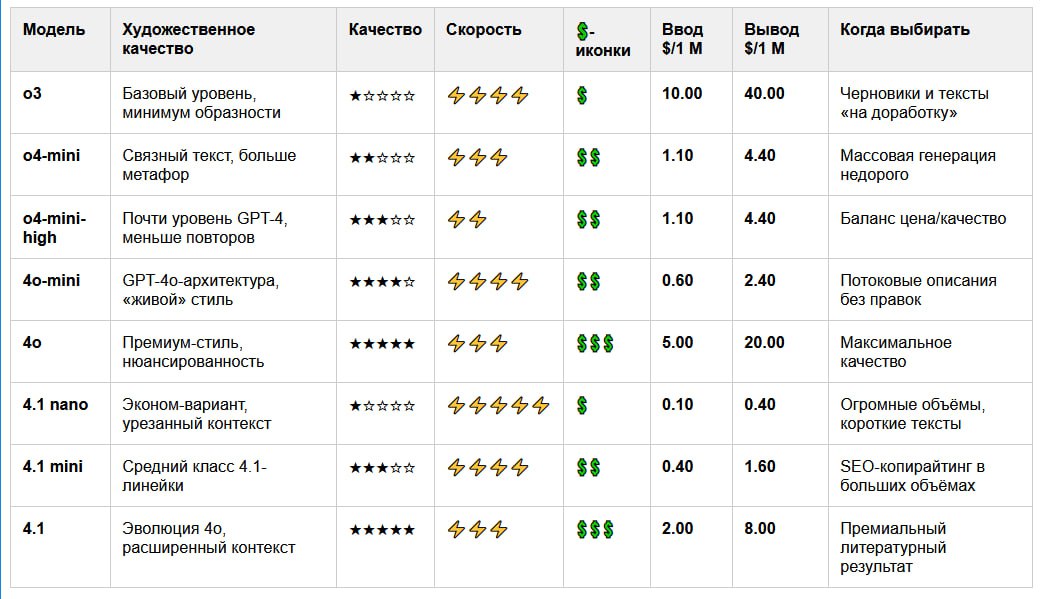
| Модель | Качество | Скорость ответа | Стоимость | Когда выбирать |
|--------------|----------|-----------------|-----------|-----------------------------------------|
| o3 | * | **** | * | Минимальный бюджет, черновые тексты. |
| o4-mini | ** | *** | ** | Массовая генерация, где важен объём. |
| o4-mini-high | *** | ** | ** | Оптимум «цена/качество». |
| 4o-mini | **** | **** | ** | Потоковые описания без доп. правок. |
| 4o | ***** | *** | *** | Когда нужен «литературный» итог. |
| 4.1 nano | * | ***** | * | Огромные объёмы, короткие тексты. |
| 4.1 mini | *** | **** | ** | Массовый SEO-копирайтинг. |
| 4.1 | ***** | *** | *** | Premium-описания, сложный сторителлинг. |### 💡 Выводы по моделям ChatGPT для генерации описаний
✅ Оптимум "цена/качество"
Модели
o4-mini-high, 4o-mini и 4.1 mini дают хорошее качество за разумную цену. Подходят для большинства задач — от лендингов до соцсетей.💎 Премиум-уровень
4o и 4.1 — для тех, кому нужен максимальный стиль, сложные тексты и литературное качество. Идеальны для продающих описаний, экспертного контента и брендового сторителлинга.⚡️ Максимальная скорость и поток
4.1 nano и o3 — супердешёвые и быстрые. Идеальны для генерации черновиков, шаблонов и массовых SEO-заготовок.🎯 Рекомендация
Если бюджет ограничен —
o4-mini или 4.1 mini.Если нужна глубина и эффект —
4o или 4.1.Если важна скорость и объём —
nano или o3.| Модель | Ввод $/1 М | Вывод $/1 М |
|--------------|------------|-------------|
| o3 | 10.0 | 40.0 |
| o4-mini | 1.1 | 4.4 |
| o4-mini-high | 1.1 | 4.4 |
| 4o-mini | 0.6 | 2.4 |
| 4o | 5.0 | 20.0 |
| 4.1 nano | 0.1 | 0.4 |
| 4.1 mini | 0.4 | 1.6 |
| 4.1 | 2.0 | 8.0 |### 💰 Сравнение моделей ChatGPT по цене и качеству
📉 Дешевле всего
*
4.1 nano — ультрабюджетный вариант (от \$0.10/\$0.40 за 1М токенов). Отличен для массовых коротких текстов.*
4o-mini — даёт "живой" стиль при цене в 2–3 раза ниже, чем у GPT‑4. Идеален для потоковых описаний.⚖️ Оптимальный баланс
*
o4-mini-high и 4.1 mini дают достойное качество и хорошую цену. Подходят для SEO, email и соцсетей.*
4o-mini — один из самых выгодных по соотношению "качество/цена".💎 Премиум-качество
*
4o и 4.1 — самые качественные, с высокой ценой. Выбор для брендовых описаний, storytelling и экспертизы.💡 Нерациональные
*
o3 — устаревшая модель, при этом дорогая (\$10 / \$40 за 1М). Использовать стоит только если очень нужны черновики с минимумом стиля.---
### 🎯 Рекомендации:
* Поток дешёвых описаний -
4.1 nano, o4-mini* Баланс цены и читаемости -
4o-mini, 4.1 mini* Стильные, глубокие тексты -
4o, 4.1* Эксперименты, черновики, тесты -
o3, o4-miniКонтакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Пост: https://t.me/ai_training_ai/9

Обучение ИИ - AI Traning
2025-06-05 15:11:21
(изм. 2025-06-05 16:46:43)
# 🐍 Как установить Python в Windows: Пошаговое руководство
👋 Хотите начать программировать на Python, но не знаете, с чего начать на Windows? Это руководство для вас!
Шаг 1: Скачиваем установщик
1. Перейдите на официальный сайт Python: [https://www.python.org/downloads/windows/](https://www.python.org/downloads/windows/)
2. Найдите последнюю стабильную версию Python. Обычно она находится вверху страницы под заголовком "Python Releases for Windows".
3. Нажмите на ссылку "Latest Python X Release - Python X.Y.Z" (где X.Y.Z - номер версии).
4. Прокрутите вниз до раздела "Files" и выберите "Windows installer (64-bit)" (рекомендуется для большинства современных компьютеров) или "Windows installer (32-bit)", если у вас старая система.
Шаг 2: Запускаем установщик
1. Откройте скачанный файл (обычно с расширением
2. Очень важный момент: В первом окне установки ОБЯЗАТЕЛЬНО поставьте галочку напротив "Add Python X.Y to PATH" (или "Add python.exe to PATH"). Это позволит вам запускать Python из командной строки из любого каталога.
3. Выберите "Install Now" для установки с настройками по умолчанию (рекомендуется для большинства пользователей).
* Если вы опытный пользователь и хотите настроить компоненты или путь установки, выберите "Customize installation".
Шаг 3: Ожидаем завершения установки
* Процесс установки займет несколько минут. Дождитесь сообщения "Setup was successful".
* После успешной установки вы можете увидеть опцию "Disable path length limit". Рекомендуется нажать на нее, чтобы избежать потенциальных проблем с длинными путями файлов в будущем (потребуются права администратора).
Шаг 4: Проверяем установку
1. Откройте командную строку (нажмите
2. Введите команду:
Если установка прошла успешно, вы увидите версию установленного Python (например,
3. Вы также можете запустить интерактивный интерпретатор Python, введя:
Вы должны увидеть приглашение
Поздравляем! 🎉 Python успешно установлен на ваш компьютер с Windows!
Теперь вы готовы погрузиться в мир программирования на одном из самых популярных и востребованных языков.
Удачи в ваших проектах! 🚀
#Python #Windows #Установка #Программирование #Новичкам
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
👋 Хотите начать программировать на Python, но не знаете, с чего начать на Windows? Это руководство для вас!
Шаг 1: Скачиваем установщик
1. Перейдите на официальный сайт Python: [https://www.python.org/downloads/windows/](https://www.python.org/downloads/windows/)
2. Найдите последнюю стабильную версию Python. Обычно она находится вверху страницы под заголовком "Python Releases for Windows".
3. Нажмите на ссылку "Latest Python X Release - Python X.Y.Z" (где X.Y.Z - номер версии).
4. Прокрутите вниз до раздела "Files" и выберите "Windows installer (64-bit)" (рекомендуется для большинства современных компьютеров) или "Windows installer (32-bit)", если у вас старая система.
Шаг 2: Запускаем установщик
1. Откройте скачанный файл (обычно с расширением
.exe).2. Очень важный момент: В первом окне установки ОБЯЗАТЕЛЬНО поставьте галочку напротив "Add Python X.Y to PATH" (или "Add python.exe to PATH"). Это позволит вам запускать Python из командной строки из любого каталога.
3. Выберите "Install Now" для установки с настройками по умолчанию (рекомендуется для большинства пользователей).
* Если вы опытный пользователь и хотите настроить компоненты или путь установки, выберите "Customize installation".
Шаг 3: Ожидаем завершения установки
* Процесс установки займет несколько минут. Дождитесь сообщения "Setup was successful".
* После успешной установки вы можете увидеть опцию "Disable path length limit". Рекомендуется нажать на нее, чтобы избежать потенциальных проблем с длинными путями файлов в будущем (потребуются права администратора).
Шаг 4: Проверяем установку
1. Откройте командную строку (нажмите
Win + R, введите cmd и нажмите Enter) или PowerShell.2. Введите команду:
python --version
Если установка прошла успешно, вы увидите версию установленного Python (например,
Python 3.11.4).3. Вы также можете запустить интерактивный интерпретатор Python, введя:
python
Вы должны увидеть приглашение
>>>. Для выхода из интерпретатора введите exit() и нажмите Enter.Поздравляем! 🎉 Python успешно установлен на ваш компьютер с Windows!
Теперь вы готовы погрузиться в мир программирования на одном из самых популярных и востребованных языков.
Удачи в ваших проектах! 🚀
#Python #Windows #Установка #Программирование #Новичкам
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
👏 1
Пост: https://t.me/ai_training_ai/7
Ответ на сообщение #4
Обучение ИИ - AI Traning
2025-06-05 13:32:44
(изм. 2025-06-05 14:42:06)
Перед использованием:
* Установите Pillow: Если у вас еще не установлена библиотека Pillow (форк PIL), откройте терминал или командную строку и выполните:
Создайте каталоги:
* Создайте каталог, куда вы поместите исходные изображения (например, input_folder).
* Создайте каталог, куда будут сохраняться обработанные изображения (например, output_folder).
Измените пути в скрипте: В разделе if name == 'main': замените 'input_folder' и 'output_folder' на реальные пути к вашим каталогам:
Запустите скрипт: Сохраните код как файл .py (например, process_gallery.py) и запустите его из терминала:
Скрипт обработает все изображения из входного каталога и поместит измененные версии в выходной каталог. Имена файлов останутся прежними. Если в выходном каталоге уже есть файл с таким же именем, он будет перезаписан.
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
convert.py
* Установите Pillow: Если у вас еще не установлена библиотека Pillow (форк PIL), откройте терминал или командную строку и выполните:
pip install PillowСоздайте каталоги:
* Создайте каталог, куда вы поместите исходные изображения (например, input_folder).
* Создайте каталог, куда будут сохраняться обработанные изображения (например, output_folder).
Измените пути в скрипте: В разделе if name == 'main': замените 'input_folder' и 'output_folder' на реальные пути к вашим каталогам:
input_images_directory = 'путь/к/вашим/исходным/изображениям'
output_images_directory = 'путь/к/каталогу/для/результатов'Запустите скрипт: Сохраните код как файл .py (например, process_gallery.py) и запустите его из терминала:
python process_gallery.pyСкрипт обработает все изображения из входного каталога и поместит измененные версии в выходной каталог. Имена файлов останутся прежними. Если в выходном каталоге уже есть файл с таким же именем, он будет перезаписан.
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Пост: https://t.me/ai_training_ai/4
Обучение ИИ - AI Traning
2025-06-05 13:32:13
(изм. 2025-06-25 02:27:48)
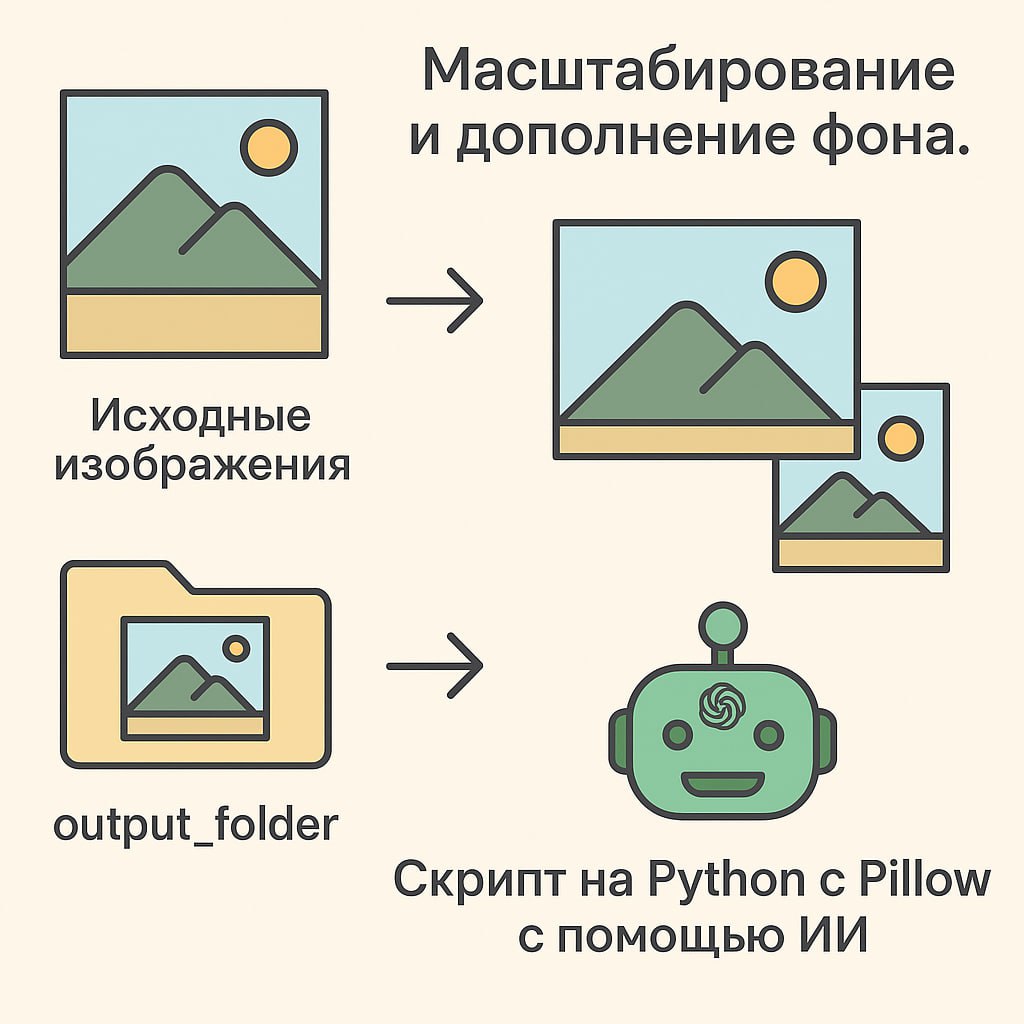
Делаем конвертер баннеров
Промпт для Google Gemini 2.5 Pro.
Загружаем картинку из этого поста или свою.
После пишем промпт:
Есть картинки, у них разные ширина и длина, нужно масштабировать их к размеру 300x250, а справа и слева и сверху и снизу заполнить цветом фона картинки, нужен скрипт на питоне.
Скрипт должен принимать каталог и преобразовать все картинки в нем.
Результат, Питон файл во вложении: https://t.me/ai_training_ai/7.
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Промпт для Google Gemini 2.5 Pro.
Загружаем картинку из этого поста или свою.
После пишем промпт:
Есть картинки, у них разные ширина и длина, нужно масштабировать их к размеру 300x250, а справа и слева и сверху и снизу заполнить цветом фона картинки, нужен скрипт на питоне.
Скрипт должен принимать каталог и преобразовать все картинки в нем.
Результат, Питон файл во вложении: https://t.me/ai_training_ai/7.
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Пост: https://t.me/ai_training_ai/3

Обучение ИИ - AI Traning
2025-06-05 13:18:41
(изм. 2025-06-05 13:20:43)
Обучение ИИ - AI Traning.
🎓 Канал для тех, кто хочет освоить ИИ с нуля
Добро пожаловать в «Обучение ИИ — AI Training» — место, где искусственный интеллект становится понятным!
📌 Что вы найдете в канале:
— Простые объяснения сложных тем (ML, нейросети, GPT и др.)
— Полезные подборки: курсы, книги, видео
— Пошаговые гайды и туториалы
— Инструменты и сервисы для обучения
— Новости и инсайты из мира AI
💬 Формат: коротко, по делу, без воды.
Подходит как новичкам, так и тем, кто уже в теме.
🔗 Подписывайся и начни обучение ИИ уже сегодня!
👉 https://t.me/ai_training_ai
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
🎓 Канал для тех, кто хочет освоить ИИ с нуля
Добро пожаловать в «Обучение ИИ — AI Training» — место, где искусственный интеллект становится понятным!
📌 Что вы найдете в канале:
— Простые объяснения сложных тем (ML, нейросети, GPT и др.)
— Полезные подборки: курсы, книги, видео
— Пошаговые гайды и туториалы
— Инструменты и сервисы для обучения
— Новости и инсайты из мира AI
💬 Формат: коротко, по делу, без воды.
Подходит как новичкам, так и тем, кто уже в теме.
🔗 Подписывайся и начни обучение ИИ уже сегодня!
👉 https://t.me/ai_training_ai
Контакты:
ТГ: @inp88
Сайты:
https://dev256.com/
https://ai-training.top/
Контакты
- Email: info@dev256.com
- Telegram: @inp88